How I built Realtime Log for Adtech on AWS
2025-05-06Learn how I designed and implemented a high-performance realtime logging system for adtech using AWS Kinesis, Lambda, and DynamoDB to optimize ad delivery algorithms with granular metrics aggregation.
2017 was one of the pivotal moments in my career as a software engineer. I came across the book titled "Designing Data-Intensive Applications", also known as DDIA, written by Martin Kleppmann. I was a backend software engineer working for Cookpad, which was offering the global recipe-sharing platform written in Rails. I was a member of inhouse advertisement technology team, where I delved myself into writing a high-performance ads delivery services where every 1ms matters. When I've read the DDIA for the first time, I felt so ashamed of not knowing anything about building systems at scale. This is the time when I seriously started reading anything about Databases, Performance Engineering, and Scalability.
One of the biggest systems I managed at the time was our Realtime Log System for Advertisement Metrics. If you have a background in adtech, you might have heard of business KPIs like "Impression" (the number of times your ads are seen), "CTR" (Click-Through Rate, the rate showing your ads are clicked), and "CVR" (Conversion Rate, the rate indicating your ads are converted to leads, like purchasing items or applying for webinars for example). This realtime log system was one of our critical components to collect metrics from servers to use for optimising ads delivery algorithm.
I can give you an example. One of our clients wants to show image banners (ads inventory) to users visiting our website. The client pays some amount of money (budget). The client tells us in the system how much impression or CTR they want to achieve with the budget (goal). Given those numbers, our system shows their banner up until the point it achieves the goal. This is a fairly simplified version of how ads delivery works, but I believe you get the point.
What does the algorithm need to make a better decision how many times to show each ad banner? The algorithm needs realtime log to make that decision. If performance metrics get lagged, there is a risk showing ads too often, leading to unoptimised ads delivery. By that, we had to build a realtime log system.
Here is a simplified architecture that we've built. At the time of working in the team, we used AWS. You can see in the diagram that we've chosen AWS Kinesis Stream as a streaming database, AWS Lambda Function as a computation layer, and AWS DynamoDB as an intermediate data store.
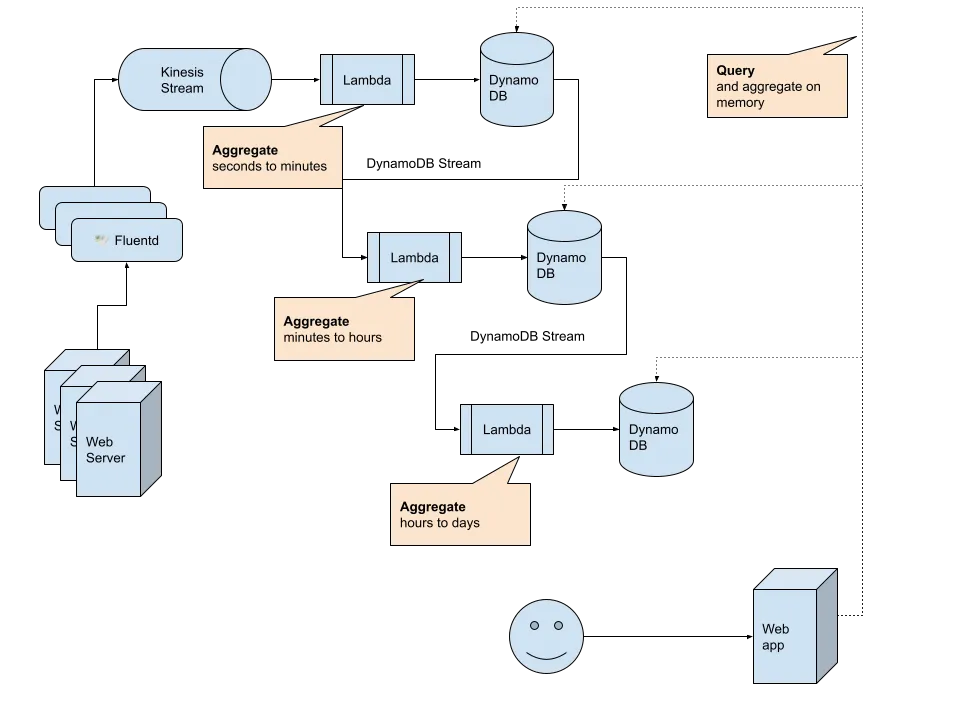
This is so-called Speed Layer, which is a realtime layer in Lambda Architecture. We had another Batch Layer which is built by Data Warehouse team on top of AWS Redshift. As DWH solution was slow to use as an input to the optimised ads delivery algorithm, we needed to build this Speed Layer.
The log stream pipeline works as follows:
- Log agent, Fluentd running as sidecars, collect logs from Rails web servers
- Fluentd sends logs to Kinesis Stream
- Speed Layer 1: aggregates logs from seconds to minutes and writes to AWS DynamoDB
- Speed Layer 2: aggregates logs from minutes to hours and writes to another DynamoDB
- Speed Layer 3: aggregates logs from hours to daily and writes to the third DynamoDB
By that, we could have enough granularity to query three different DynamoDB based on read workload usecases. When the algorithm needs only recent 10min data, then the system queries only from the second DynamoDB. When the algorithm needs to take into account of minutes trend with hourly data, then it queries from two DynamoDB.
As far as I can recall, our inhouse ads delivery system served several thousand RPS, with around 30 running instances that were auto-scaled.
The Batch Layer was still necessary to get more accurate data. By having the Speed Layer, we could achieve far more flexible ads delivery algorithm and optimised budget performances.
Conclusion
This was the first data-intensive application that I got involved after reading DDIA. Since then, I have been looking for hard and fun technical challenges that require careful data modeling with picking right database tech stacks with keeping all of available performance tunings in place. I still enjoy this after 8 years I've first read that book.
Building the Realtime Log System taught me invaluable lessons about data-intensive applications. The multi-layered approach with different time granularities provided both performance and flexibility for our adtech algorithms.
This project fundamentally changed how I think about data systems. It demonstrated that thoughtful data modeling is just as crucial as code quality when building resilient, high-performance applications at scale. For any engineer embarking on similar challenges, I highly recommend starting with a solid foundation in data systems theory (like DDIA provides) before diving into implementation.