Index-free Adjacency in Graph Databases
2021-09-24An exploration of index-free adjacency in graph databases like Neo4j, explaining how this approach enables efficient traversal of relationships without index lookups and why it provides superior query performance for connected data compared to traditional relational databases.
When diving into the internal implementation of graph databases, you will likely come across the term "Index-free Adjacency."
For example, you might encounter statements like: "In graph databases with a graph-native implementation, high query performance is achieved thanks to Index-free Adjacency."
This post will introduce the concept of Index-free Adjacency.
What is an Index?
Before discussing Index-free Adjacency, let's first review what an index is in a relational database (RDBMS).
An index is essentially a "lookup table." By pre-creating an index, databases can quickly retrieve specific data rather than scanning the entire dataset.
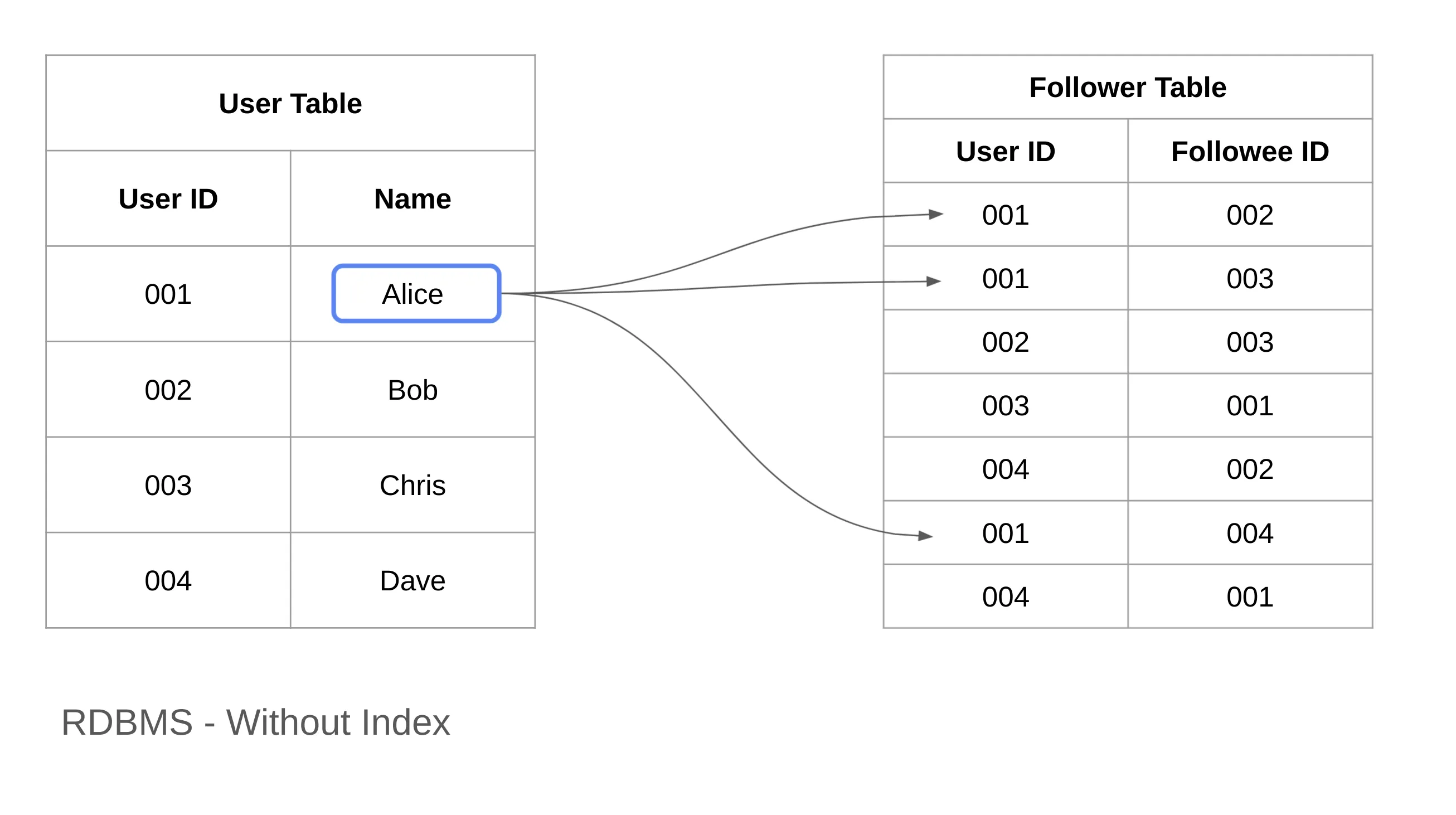
Example: RDBMS Without Indexes
Consider a social networking application where we query the database to find "users that 'Alice' follows."
Using an RDBMS, we model the data as follows:
- A
Usertable stores user information. - A
Followertable represents follow relationships between users.
To find the users that Alice (User ID = 1) follows, we search the Follower table for rows where User ID == 1.
Without an index, the system must scan all rows sequentially to find matches. If the Follower table contains N rows, the search cost is O(N), meaning query performance degrades linearly with data size.
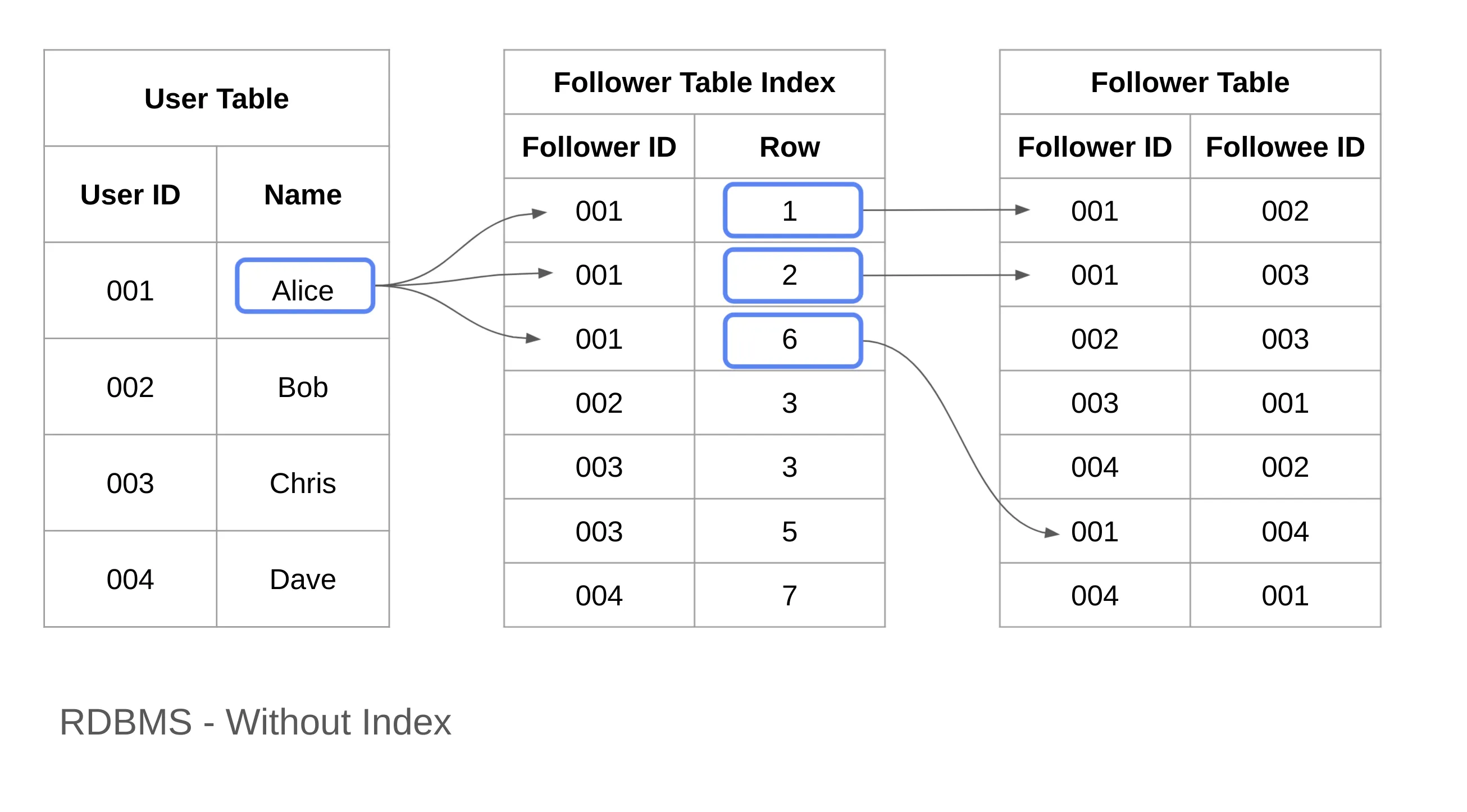
Example: RDBMS With Indexes
Now, let’s introduce an index to improve query performance.
An index functions like a dictionary’s index, mapping keywords to page numbers. In our case, we create an index mapping Follower ID to the corresponding row number in the Follower table.
Hash<K, V> = <Int, Int>
K = Follower ID
V = Row Number
Depending on the underlying data structure, indexing typically reduces query complexity to O(log(N)).
Since the index stores the row number, accessing the actual row takes O(1), resulting in an overall lookup cost of O(log(N)).
The Downsides of Indexing
Indexes come with trade-offs, particularly in maintenance costs.
Imagine publishing a revised edition of a dictionary—if new words are added or removed, the index at the back must be updated accordingly.
Similarly, in RDBMS, indexes are separate physical structures stored on disk. When database records are modified, indexes must be updated as well. This results in:
- Decreased write performance due to the additional index maintenance.
- Increased storage usage to accommodate the index structure.
While indexing improves query speed, it can be a disadvantage for write-heavy applications, making index creation a trade-off decision.
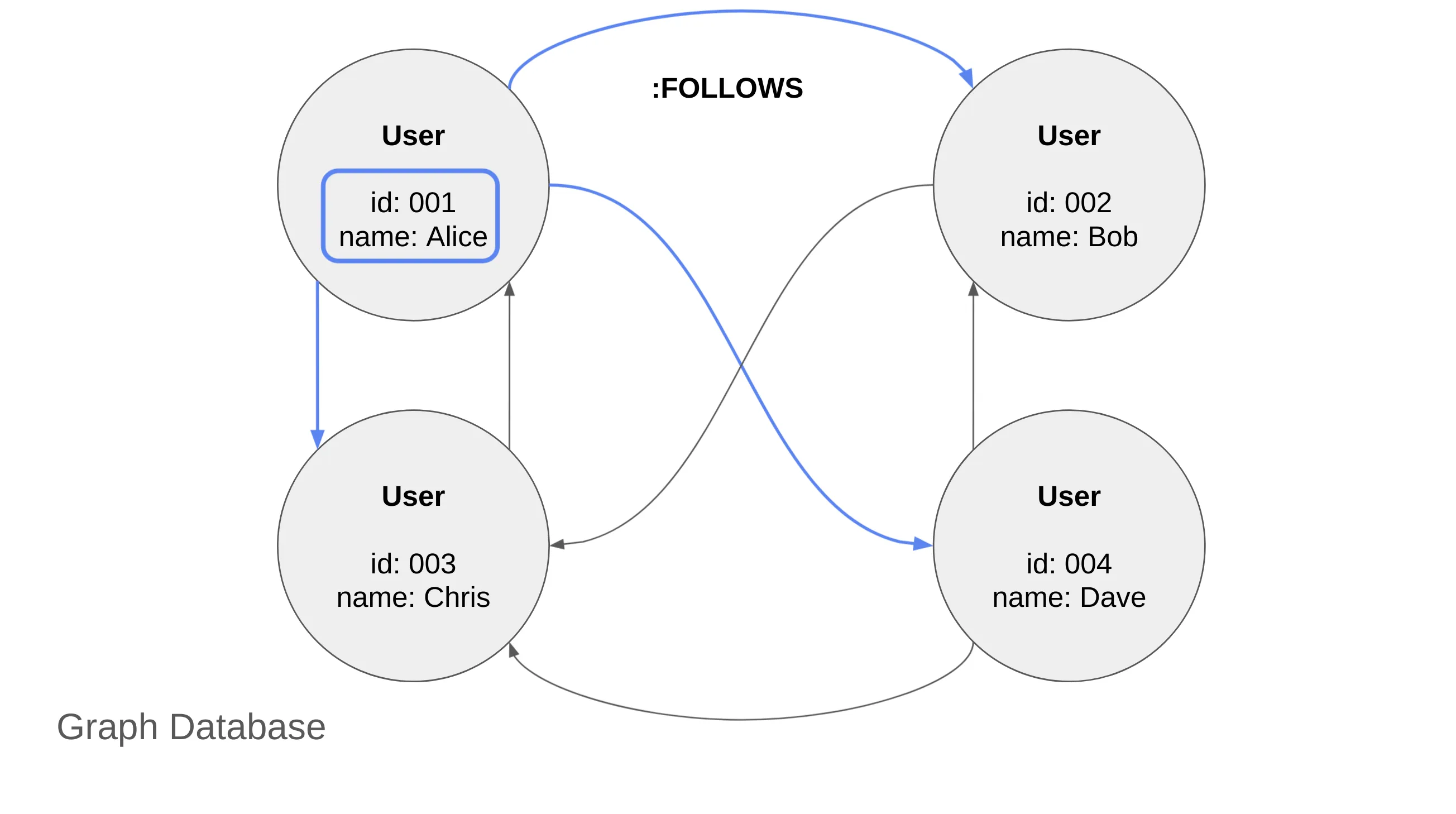
Example: Graph Databases
Graph-native databases—those implementing Index-free Adjacency—store relationships directly on disk.
For example, in Neo4j:
- Nodes represent entities.
- Relationships (edges) between nodes are stored as direct references (pointers).
Since nodes reference related nodes via direct pointers, there is no need for an index to look up relationships. This means that related nodes are always adjacent on disk.
What is Index-free Adjacency?
Index-free Adjacency literally means "adjacency without an index." In other words, related nodes are stored close together without requiring an index lookup.
As a result, querying directly connected nodes always takes O(1) time.
For example, finding "users that Alice follows" in a graph database is an O(1) operation, as Alice’s node directly points to the followed users’ nodes.
This is the reason why graph databases with Index-free Adjacency achieve superior query performance.
Conclusion
This post compared Index-free Adjacency in graph databases with traditional indexing in RDBMS to highlight the performance benefits of graph-native storage structures.