Inside My Blog's Development: One Year with Remix
2025-04-15A deep dive into the technical architecture of this blog after migrating from Gatsby to Remix, focusing on content processing, data modeling, and performance optimization techniques.
It's been exactly one year since I migrated this blog from Gatsby to Remix, and I'm pleased with how it has evolved. In my previous post, I explained why I made the switch. Now, I want to share the technical details of how this blog is built and the optimizations I've implemented.
Architecture Overview
At its core, this blog is a Remix application deployed on Cloudflare Pages. It uses a hybrid approach: pre-processing markdown files at build time while leveraging Remix's server-side rendering capabilities for delivery. This gives me the benefits of both static site generation and server-side rendering.
+----------------------------+
| Content Creators |
| (Write Markdown Files) |
+------------+---------------+
|
v
+----------------------------+
| Build Process |
| (Pre-process Markdown) |
| |
| - Parse Frontmatter |
| - Validate Metadata |
| - Convert to HTML |
| - Generate JSON Output |
+------------+---------------+
|
v
+----------------------------+
| Cloudflare Pages |
| (Deploy Static Assets) |
| |
| - Global CDN Distribution |
| - Asset Optimization |
+------------+---------------+
|
v
+----------------------------+
| Remix Application |
| (Server-Side Rendering) |
| |
| - Data Loaders |
| - Nested Routes |
| - Recommended Posts |
+------------+---------------+
|
v
+----------------------------+
| End Users (Browsers) |
+----------------------------+
Content Processing Pipeline
Markdown Processing
All blog posts are written in Markdown with frontmatter metadata. During the build process, each markdown file undergoes several transformations:
- Parsing: Files are parsed using gray-matter to extract frontmatter and content
- Validation: Tags and required fields are validated against a predefined schema
- HTML Conversion: Markdown content is converted to HTML using remark
- Output Generation: JSON files are created for each post with all necessary data
Here's a simplified view of how this process works:
// Content processing pipeline
function parseMarkdown(fileContent, filePath) {
// Extract frontmatter and content
const { data, content } = grayMatter(fileContent);
const { title, date, description, tags } = data;
// Validate required fields
validateRequiredFields(title, date, description);
validateTags(tags);
// Convert to HTML
const htmlContent = remarkProcessor.process(content).toString();
return { title, date, description, tags, htmlContent };
}
This pre-processing approach dramatically reduces the runtime overhead by avoiding markdown parsing during request handling.
Tag System
The tag system is optimized for both performance and usability:
- Tags are validated against an allowlist to prevent typos and maintain consistency
- A tag-posts index is built during pre-processing to enable fast lookups
- Tag counts are pre-computed and sorted by popularity
This attention to data modeling ensures that tag-related operations remain efficient even as the blog grows.
Recommended Posts Engine
One feature I'm particularly proud of is the recommended posts system, which suggests related content based on tag similarity:
- Relevance Scoring: Posts are scored based on the number of shared tags
- Recency Balance: When relevance scores are equal, newer posts are prioritized
- Pre-computation: Recommendations are calculated during build time, not at request time
The algorithm prioritizes computational efficiency while ensuring relevant recommendations:
// Conceptual overview of recommendation algorithm
function findRelatedPosts(currentPost, tagPostsIndex) {
const relevanceMap = new Map();
// For each tag, find posts that also have that tag
for (const tag of currentPost.tags) {
const postsWithTag = tagPostsIndex.get(tag) || [];
// Increase relevance score for each matching post
for (const post of postsWithTag) {
if (post.slug !== currentPost.slug) {
const entry = relevanceMap.get(post.slug) || { post, score: 0 };
entry.score++;
relevanceMap.set(post.slug, entry);
}
}
}
// Sort by relevance score then by date
return Array.from(relevanceMap.values())
.sort((a, b) => b.score - a.score || new Date(b.post.date) - new Date(a.post.date))
.slice(0, 3);
}
By pre-computing these recommendations, I avoid costly runtime calculations while still providing personalized content suggestions.
Leveraging Remix's Architecture
Data Loading
Remix's loader pattern has been transformative for how data flows through the application:
// Conceptual example of a Remix loader
export async function loader({ params }) {
const post = await getPost({
slug: params.slug,
postType: params.postType
});
return json({ post, recommendedPosts: post.recommendedPosts });
}
This unidirectional data flow provides several benefits:
- Clear Separation: Data loading is distinctly separated from UI rendering
- Error Handling: Proper HTTP status codes for missing content
- Server-First Approach: Data is loaded on the server before any client-side code runs
Route-Based Design
The blog's URL structure is cleanly represented in the routing system:
/$postType._index.tsx: List view for blog posts or pages/$postType.$slug.tsx: Individual post view/$postType.tags._index.tsx: Tags overview/$postType.tags.$tag.tsx: Posts filtered by tag
This nested routing approach makes the codebase more navigable and maintainable.
Performance Optimization
Performance Score
One of my goals was to achieve near-perfect Lighthouse scores, and I'm happy to report success:
| Metric | Score (/blog) |
Score (/blog/${slug}) |
|---|---|---|
| Performance | 100 | 99 |
| Accessibility | 100 | 100 |
| Best Practices | 96 | 96 |
| SEO | 100 | 100 |
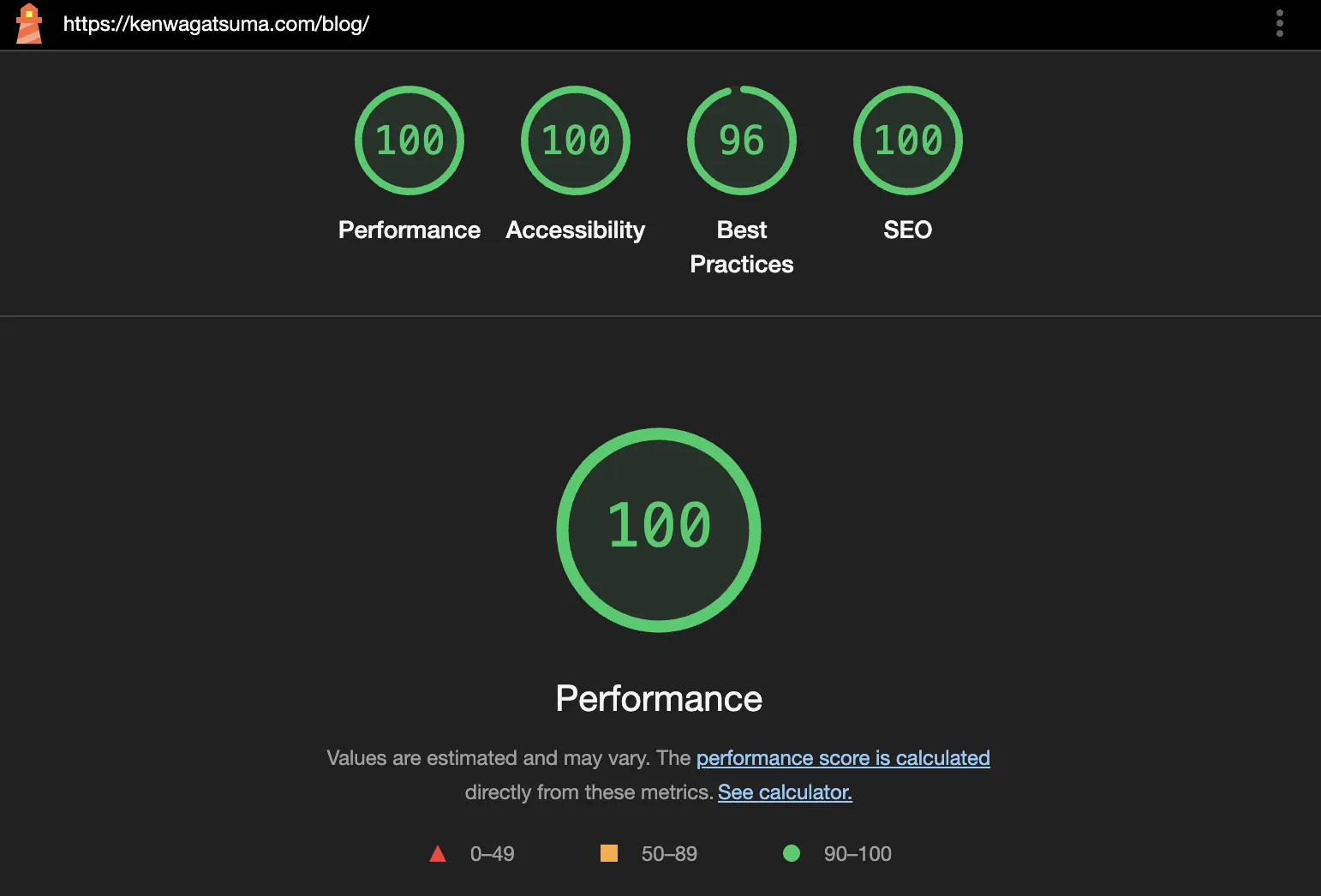
These scores aren't just vanity metrics—they reflect real user experience improvements.
Time and Space Complexity Considerations
Every feature was implemented with algorithmic efficiency in mind:
- O(1) Post Lookup: Posts are accessed by slug as direct JSON imports
- Optimized Tag Filtering: Pre-built indices ensure O(1) lookup for posts by tag
- Memory Usage: JSON files contain only the necessary data, with no redundant information
Bundle Size Optimization
The client-side JavaScript bundle is kept minimal by:
- Leveraging server-side rendering for the initial content
- Avoiding unnecessary client-side libraries
- Using code splitting for route-based components
Lessons Learned
After a year with Remix, here are my key takeaways:
- Server-First Thinking: Designing with server-side rendering in mind leads to better performance
- Data Modeling Matters: Well-designed data structures simplify both development and runtime performance
- Build-Time Processing: Moving complexity to build time simplifies the runtime experience
What's Next?
Looking forward, I plan to explore:
- Edge Caching Strategies: Further optimizing content delivery
- Enhanced Search: Implementing a more sophisticated search system
The flexibility of Remix's architecture will make these enhancements relatively straightforward to implement.
Conclusion
Moving to Remix has been a positive experience for both development workflow and site performance. The framework's emphasis on web fundamentals aligns perfectly with my goals for this blog—delivering content efficiently while maintaining a straightforward development process.
If you're considering a similar migration or building a new content-focused site, I hope this technical overview provides some useful insights. The combination of build-time processing and server-side rendering offers the best of both worlds: the performance of static sites with the flexibility of dynamic applications.
Feel free to reach out if you have questions about any aspect of this implementation!