Introduced Semantic Search on This Blog
I implemented Semantic Search on my blog. The strongest motivation is as an experiment for VectorDB (Pinecone).
Introducing the technical architecture. First, let's talk about the index update flow. Extract metadata from blog articles submitted as Markdown files at build time using Gatsby. Use the URL and title of the article as metadata. Next, send an HTTP POST request to Cloudflare Workers. In Workers, first UPSERT to Cloudflare D1 (SQLite). Use db.batch to collect Prepared Statements and limit the round trip to D1 to one time.
Next, vectorize the metadata. Using BAAI general embedding of Cloudflare AI binding, convert string information to vector representation and UPSERT to Pinecone (VectoreDB). The upper limit vector for UPSERT at one time is 20K so batching is not required at the moment and a single HTTP API call does the job.
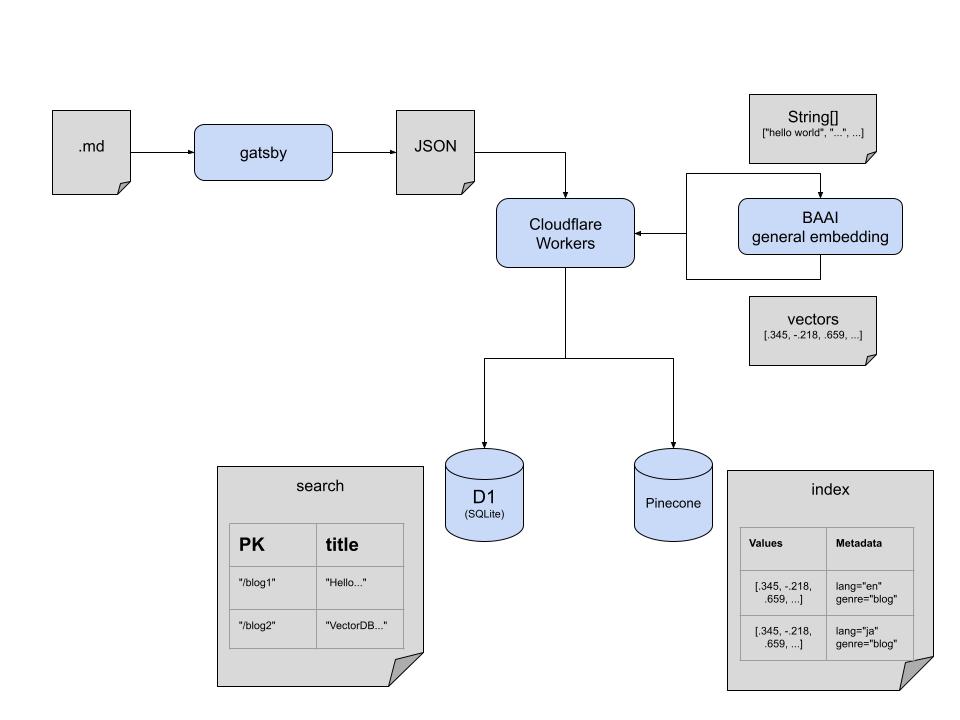
Now that I have explained the update flow, I will also explain the search flow. Add another endpoint in Cloudflare Workers to receive search terms in an HTTP POST request. Use the same model to express the search term as a vector, and then query Pinecone. I use Metadata to be able to separate the results between English blogs and Japanese blogs. Pinecone implements Single-Stage Filtering. Single-Stage Filtering seems to overcome the performance degradation caused by brute force checking with simple pre-filtering and the degradation of search result quality caused by simple post-filtering.
{
"metadata": {
"lang": "(en|ja)",
"genre": "blog"
}
}
Actually, I originally implemented it using Neo4j's Vector search index instead of Pinecone. Prototyping on Neo4j went well, so I tried to use it from Cloudflare Workers first. But I gave up because Neo4j client is unable to cross Cloudflare's network because Neo4j implements Bolt Protocol instead of HTTP.
Now, what should I hack next? As a Site Reliability Engineer who loves databases, I would like to compare and consider other VectorDBs, such as Cloudflare Vectorize. It would be fun to tune it to improve search accuracy by using other Text Embedding models, increasing the number of vectors, or using other types of Vector Similarity other than Cosine Similarity.