Dynamic Secondary Hashing
Hot Partitioning Problem
One of the common real-world issues encountered in partitioning is known as the Hot Partition problem. Skewed Workloads or Hot Spots are also used almost synonymously. This is a state where the load is concentrated on a specific partition, failing to distribute the load across the entire platform.
For example, consider building a multi-tenant e-commerce application. Suppose you partition the database by Shop ID. Let's say you are using simple Hash Partitioning.
Now, what kind of load would you expect if a super popular fashion brand conducts a large-scale, one-hour sale? Would it scale sufficiently if you were using Hash Partitioning?
A common failure pattern is that the partition assigned to the data of that fashion brand experiences a sudden surge in load during the sale. The database goes down and cannot handle the requests necessary for the sale. Moreover, due to the multi-tenant configuration, other stores that store data in the same partition are also affected.
In the case of social networks like Twitter or Facebook, a celebrity's account with millions of followers can cause the partition storing that account's data to crash if partitioned normally. This is sometimes referred to as the Celebrity problem.
How to solve Hot Partitioning
So, how do we solve the Hot Partition problem? There are several methods.
First, let's introduce a simple example from the DDIA book ("Designing Data-Intensive Application"). If a specific key is expected to become highly loaded, a proposal is to append a randomly generated integer.
However, this simple solution has its drawbacks. While it benefits from load distribution during writes, it requires gathering distributed data from multiple partitions during reads, leading to a performance trade-off for read workloads. This is a typical gather/scatter pattern.
The DDIA book concludes this section by stating, "In the near future, data systems might automatically detect and handle skewed workloads, but for now, each implementation must consider the trade-offs."
However, this book was published in March 2017. Six years have passed since then. Are there any new research results or achievements? As I was participating in the second reading circle of the same book, I was looking for something valuable and came across an interesting paper co-authored by Alibaba Group and Georgetown University in 2022.
"ESDB: Processing Extremely Skewed Workloads in Real-time" is a paper that introduces how Alibaba, which builds multi-tenant e-commerce sites, improves performance for skewed workloads, as mentioned above, using Dynamic Secondary Hashing and other optimization techniques. It's a very interesting case, so let's delve into it here.
Problems to solve
The performance issues faced by multi-tenant e-commerce sites like Alibaba and Shopify are particularly skewed and unpredictable workloads during sales or promotions like BFCM. In other words, data is skewed to certain partitions, and the spikes are unpredictable.
Another challenge is that the workload distribution in the sellers' database is extremely skewed because of the tremendous variation of the numbers of transactions conducted by different sellers. The variation is further magnified at the kickoff of major sale and promotion events during which the overall throughput increases dramatically.
Imagine an online store that usually has a maximum of 10K RPM, but due to a one-hour promotion conducted worldwide, it suddenly has to handle millions of requests.
Moreover, since it involves payments for purchasing products, a certain amount of write load is also expected, not just reads. If it were just reads, warming up the cache might solve the issue, but in an online store with product inventory, that's not enough.
You need to scale both the spiking write workload and the flooding read workload while maintaining consistency, all within a high-intensity one-hour window. There's no more interesting challenge than this.
Solution
The paper introduces several optimization techniques, but this article will focus on the core method of partitioning, Dynamic Secondary Hashing.
However, before explaining Dynamic Secondary Hashing, it is necessary to introduce the conventional methods.
First, let's organize the problem. The issue here is that the write workload assigned to partitions for certain keys (e.g., User ID, Shop ID) spikes suddenly, causing the node assigned to that partition to crash.
Double hashing
One solution to this is Double Hashing, implemented in Elasticsearch, HBase, and OpenTSDB. This method further divides the data by repeating hashing.
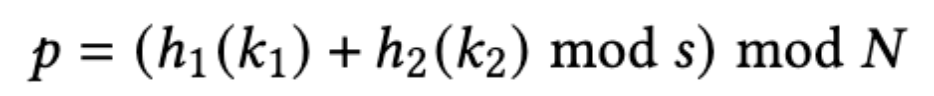
The formula for Double Hashing. h1 and h2 are different hashing algorithms. k1 and k2 are different keys, for example, k1 is the Tenant ID that distinguishes stores, and k2 is the Transaction ID. s is an important lever and tuning point. The larger this value, the more the data can be distributed. However, the CPU cost required for query execution increases, and more data needs to be aggregated when returning data, resulting in decreased performance.
Here's an analogy. Imagine cutting a hamburger steak for a toddler who has just started eating meat. Since the child is still small and cannot fit the whole piece in their mouth, the parent, who wants the child to eat meat and get protein, chops it into smaller pieces. That's the image.
Double Hashing seems good. Why isn't Double Hashing enough?
Hashing is not something that gets better the more you divide it. While it does distribute large partitions, it decreases read performance because data must be aggregated from multiple partitions. It's a gather/scatter pattern.
Even a delicious charcoal-grilled hamburger loses its juicy flavor if cut too much before eating. If it fits in the mouth, it should be enjoyed as it is.
Dynamic Secondary Hashing
So, the simple idea is to "distribute data only for large partitions and simply hash small partitions." If we analyze the data in real-time and dynamically decide whether to hash, wouldn't that work? Previously, we changed the "s" parameter at each deployment timing based on data analysis, but now we can dynamically change it.
That's where Dynamic Secondary Hashing comes in. As the name suggests, it dynamically decides whether to perform Secondary Hashing (second hashing).
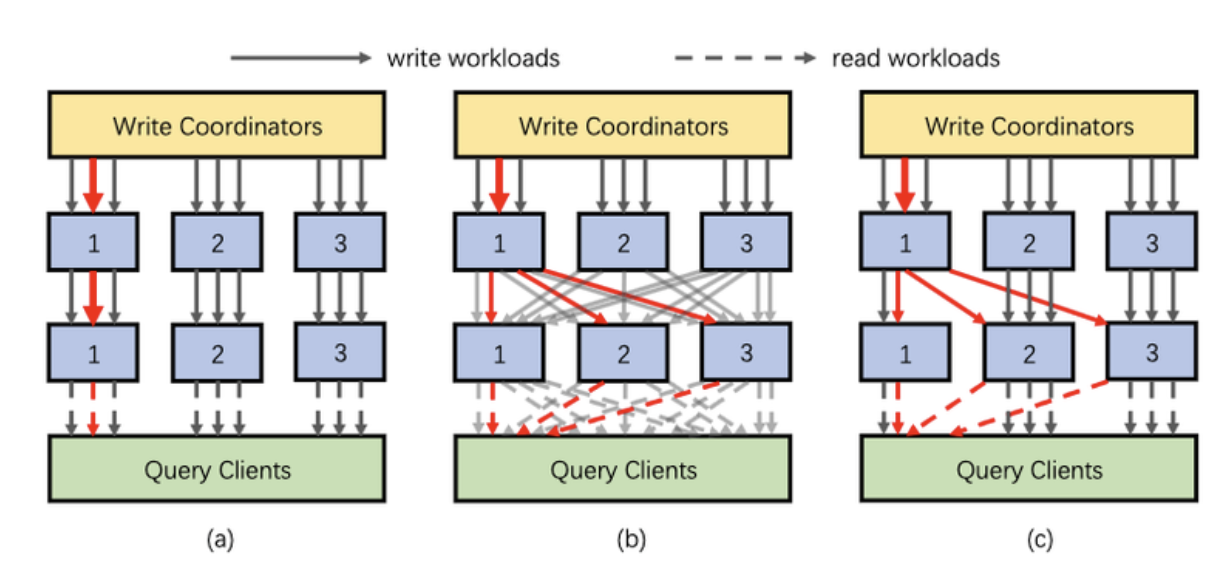
(a) is Hashing. The same key is assigned to the same partition. (b) is Double Hashing, where all keys are assigned to multiple partitions. (c) is Dynamic Secondary Hashing. The thick red arrows indicate the amount of data, and only the keys with large amounts of data are Double Hashed.
Do you remember the formula for Double Hashing? By adjusting the tuning parameter "s," you could balance the trade-off between distribution and query efficiency. The idea of Dynamic Secondary Hashing is to use real-time metrics to dynamically change this tuning parameter "s."
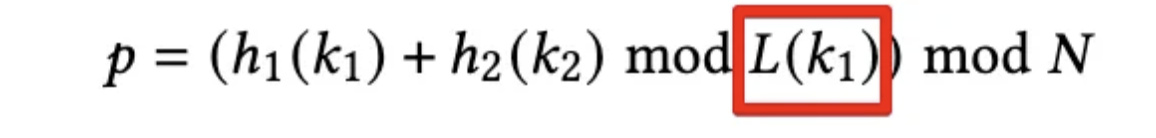
The formula for Dynamic Secondary Hashing. The difference from Double Hashing is that the parameter "s," which balanced the trade-off between distribution and query efficiency, is replaced by L(k1). This is called the Workload-adaptive offset function. It dynamically decides based on real-time metrics of Key 1 (k1).
Let's return to the hamburger example. A child who sees a hamburger for the first time doesn't know if it's delicious. Since they won't eat it whole, the parent needs to chop it into the smallest possible size to feed it. However, based on the child's feedback of wanting more of the delicious charcoal-grilled hamburger, the size of the chopped pieces can be adjusted. This is a typical feedback mechanism in system thinking.
However, as always, Double Secondary Hashing is not a silver bullet. It must be used correctly according to the prescribed usage and dosage.
The biggest challenge is that it can break Read-your-writes Consistency. This is because the mapping of where Key 1 (k1) data goes to which partition is constantly changing, making it unclear where each record is at any given time in the past.
Specifically, the same data might be duplicated in different partitions, or the final result of a query aggregating distributed data might be unintended.
As a solution, the paper suggests storing the past Secondary Hashing Rule List in tuples, allowing for retrospective calculations of past parameter changes.
This data should be volatile upon restart, so it would be stored in memory during runtime. However, depending on the implementation of the Workload-adaptive offset function, the parameter "s" might change frequently, causing the list to bloat. Although the paper does not introduce specific implementations or drawbacks, this is one point to consider.
Additionally, to ensure consistency, all Coordinator processes need to share the same Rule List. Therefore, a typical consensus process in distributed systems is required. There are several practical implementations of consensus algorithms, from Paxos to Raft and ZAB. The paper mentions implementing a variant of the two-phase commit similar to Spanner's Commit wait for sufficient reasons.
Conclusion
In summary, we introduced Dynamic Secondary Hashing, an algorithm implemented at Alibaba to detect skewed workloads and dynamically distribute partitions.
The key to Dynamic Secondary Hashing is the implementation of the Workload-adaptive offset function, which dynamically changes the "s" parameter of Double Hashing. By trying out several implementation patterns and gathering data, each can find the optimal algorithm that fits their business requirements and application nature.
It is also worth considering the increased edge cases that need to be addressed to ensure consistency. This is generally a difficult area to test, so how well these edge cases can be addressed before going into production will be crucial.
If anyone has implemented Dynamic Secondary Hashing or similar ideas, I would love to hear your feedback.