Blog Relevant Tags Internals
つい先日、本ブログに、Relevant Tags の機能を実装しました。
例えば、#neo4j タグページの下部に、以下の UI が追加されていることに気づいた方もいらっしゃるかもしれません。
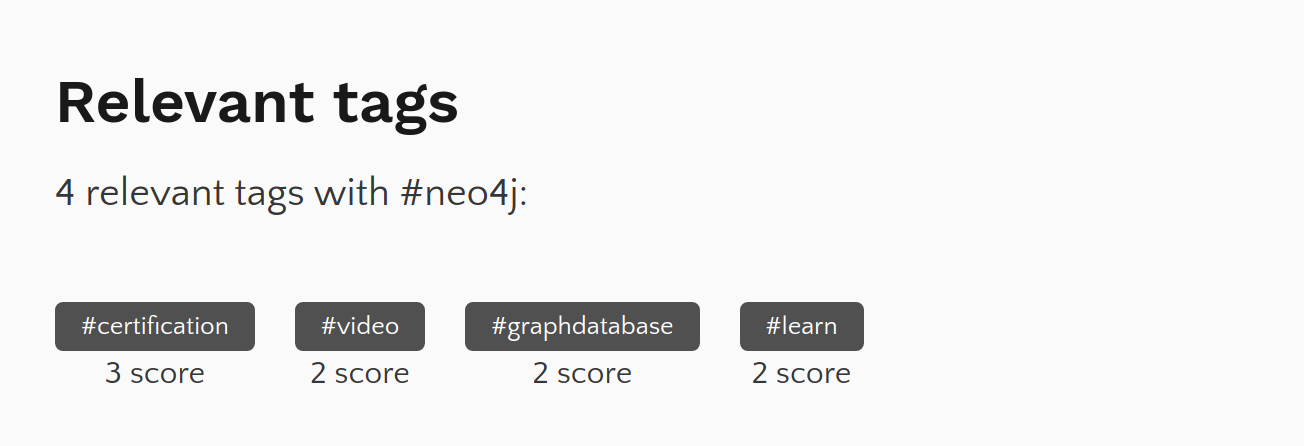
実は、このタグの関連性を計算するにあたって、Neo4j Aura を利用しています。
本ブログでは、Relevant Tags の実装の裏側について紹介します。
課題
本ブログでは、各ブログごとに任意のタグ を追加しています。ブログは複数のタグをつけることが可能で、タグ毎の横断検索も実装しています。
ここで、タグの数が増えてくると、タグ毎にある程度の関連性が生まれてきます。例えば、#neo4j タグは #graphdatabase タグと同時に利用されることが多かったり、#blog タグは #gatsby タグと同時に利用されることが多かったり、といったケースです。
あるタグに興味を持ってくれた読者の方が、関連するタグにも興味を持ってくれる可能性は高いと仮定します。この時、タグ一覧を見てくれている読者に、関連性の高いタグへの動線を提供できれば、より多くのブログを読んでくれることになるかもしれません。
そのため、タグ同士の関連性を計算することにしました。
データモデリング
まずはじめに、どのようにデータをモデリングしていくかを考えます。
今回のデータモデリングはシンプルです。ブログの投稿を表す (:Post) ノードと、タグを表す (:Tag) ノードだけで十分でしょう。
また、「タグが付与されている」という状態については、-[:TAGS]-> リレーションで表現しましょう。
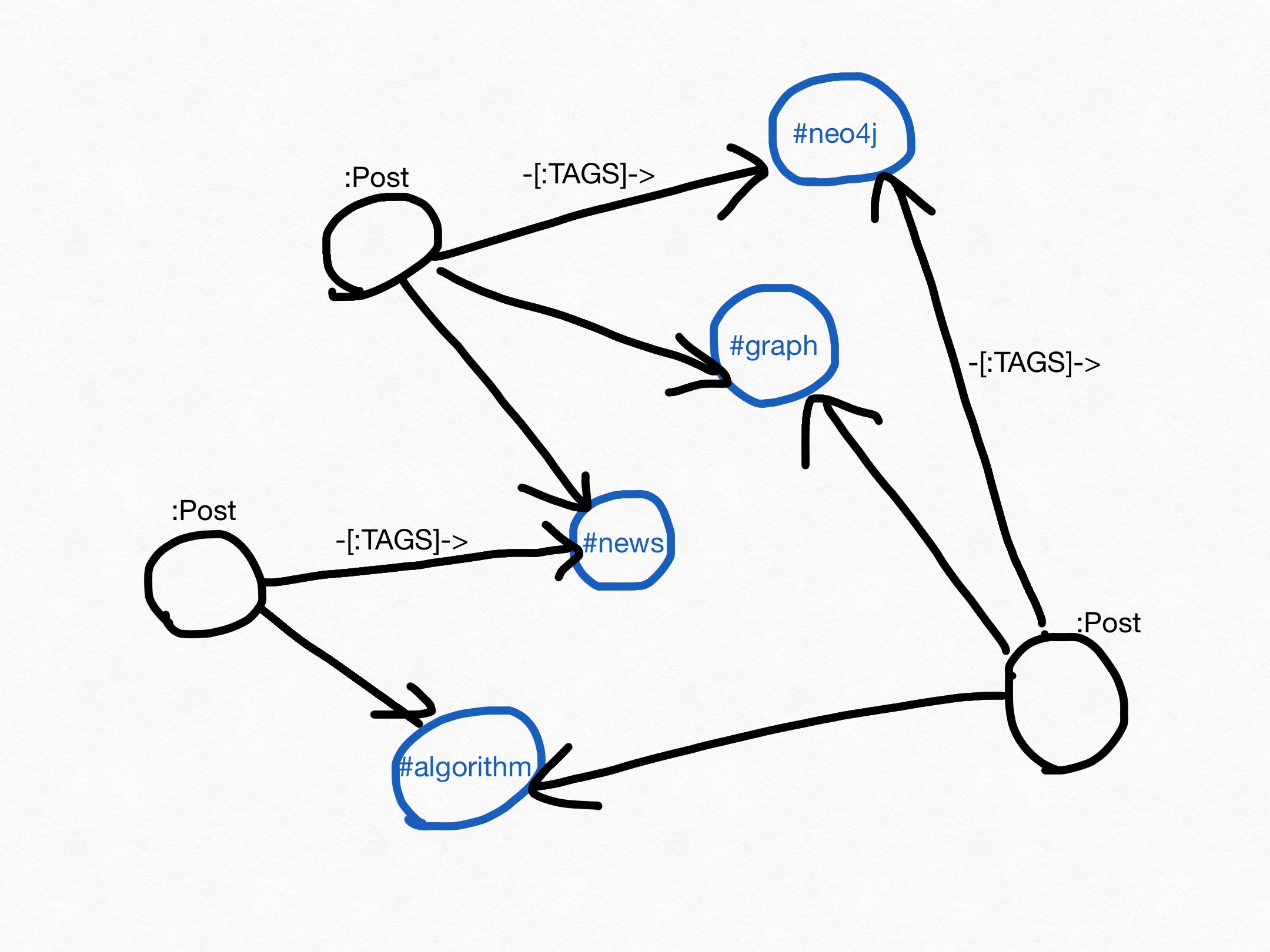
次に、「関連性」をどのように計算するか、アルゴリズムを選定しましょう。
グラフアルゴリズムには、ノード間の近接性をスコアで表現するアルゴリズムが幾つか存在します。Graph Data Science Library の提供するアルゴリズムも使えるかもしれません。
ただし、今回はまだブログ数もタグ数も始めたばかりのため決して多くはなく、あくまで Minimum Viable Product (MVP) 段階です。
したがって、「関連性」については、シンプルに 「同じブログで同時にタグ付けされたタグ同士は関連性スコアが 1 ある」 という前提を置き、関連性スコアの合計で判断することにしました。
アーキテクチャ
本ブログは、Gatsby を利用して、事前に静的 HTML をビルドし、Netlify でホスティングしています。これは、SEO やパフォーマンスの観点から、可能な限り動的な部分を無くしたいという意図からの技術選定です。
したがって、関連性スコアをページ表示時に動的に計算するのではなく、ページをビルドするタイミングで事前に計算しておいた関連性スコアを利用する方針を採用しました。
これは、ページを訪れた時に裏側で Neo4j グラフデータベースにクエリを投げる必要もなく、パフォーマンスの観点から優れています。また、グラフデータベース接続のクレデンシャルをどう管理するかや、インフラ側の構成の複雑性からもメリットが有ります。
gatsby build 実行時に、全てのブログ記事のメタデータを利用することができます。このタイミングで、メタデータから Cypher クエリを動的にテンプレート生成し、Neo4j グラフデータベースに対してクエリを実行、タグスコアを計算して返却する形にしました。
Neo4j グラフデータベースとしては、想定ノード数や求められるパフォーマンスの要件が高くないことから、Neo4j Aura の Free Plan を採用しました。
実装
ブログは Markdown で生成し、gatsby-transformer-remark を利用しています。したがって、allMarkdownRemark を利用し全てのブログのメタ情報とタグを取得します。
{
postsRemark: allMarkdownRemark(
sort: { frontmatter: { date: DESC } }
) {
edges {
node {
fields {
slug
}
frontmatter {
tags
}
}
}
}
}
次に、ブログごとに対応する (:Post) ノードと (:Tag) ノード、及びそれらの -[:TAGS]-> リレーションを追加する Cypher クエリを生成します。例えば、本記事に関しては以下のようなクエリになります。
UNWIND ['blog','gatsby','neo4j','datamodeling','neo4jaura','cypher'] AS t
MERGE (tag:Tag {value: t})
MERGE (p0:Post {id: 0, slug: '/2021-10-04-blog-relevant-tags-internals/'})
MERGE (p0)-[:TAGS]->(tag);
これを実行すると、本記事執筆時点では、以下のようなグラフネットワークが作成されます。
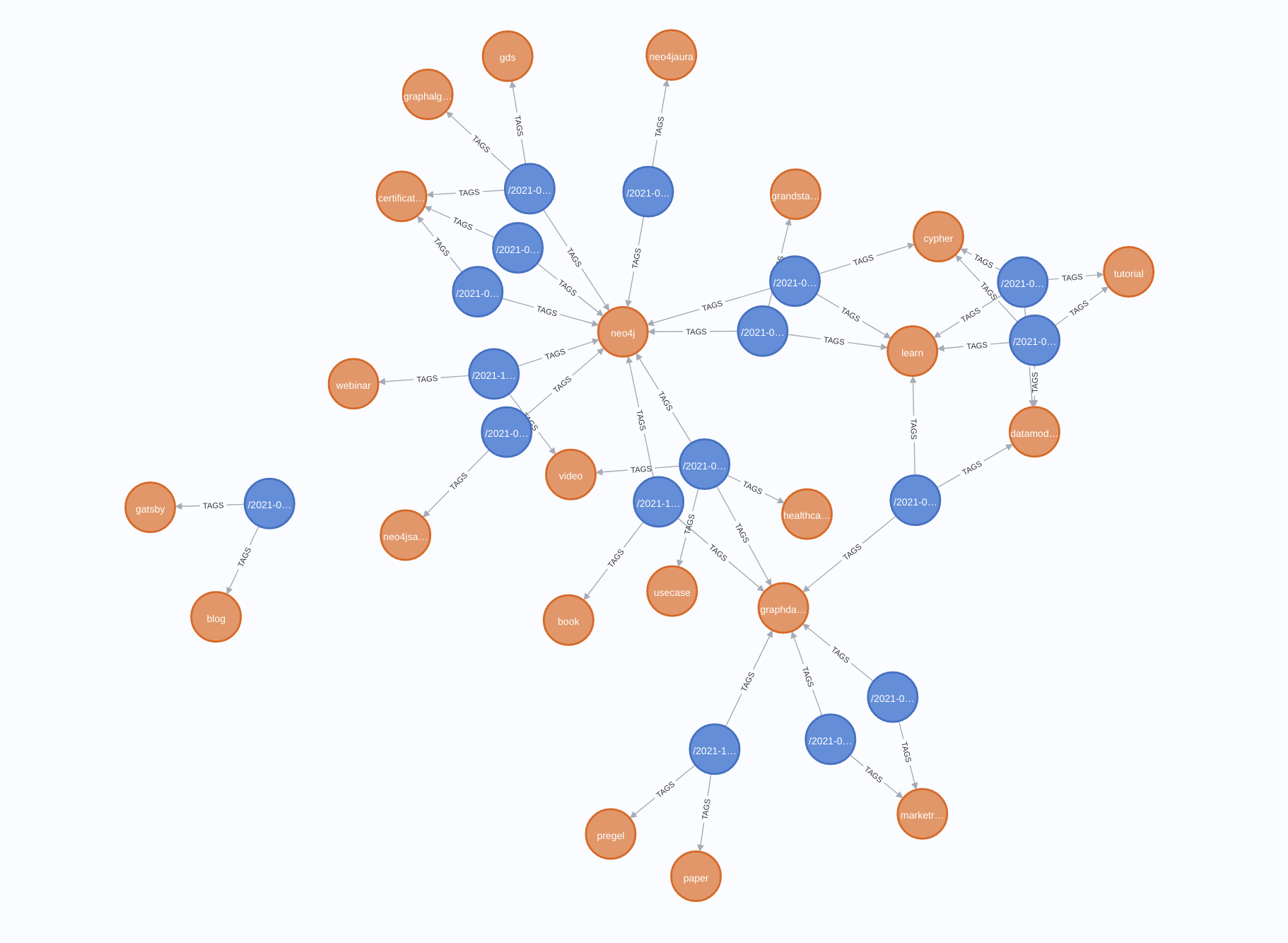
最後に、タグ同士の関連性スコアを計算します。今回は同じブログ記事に同時にタグ付けされているタグ同士であればスコアをカウントしたいので、以下のような Cypher クエリになります。
MATCH p=(t1:Tag)<-[:TAGS]-(:Post)-[:TAGS]->(t2:Tag)
WITH t1, t2, count(p) as score
WHERE score > 1
RETURN t1.value as tag1, t2.value as tag2, score
ORDER BY t1.value ASC, score DESC`
後は、ここで得られたスコアを利用して、タグ毎の個別ページに上手く UI として組み込んであげれば完成です。
最後に
以上、本ブログに実装した Relevant Tags の設計や実装について公開しました。
データモデリングとしてはシンプルな例であるものの、実際のアプリケーションに Neo4j グラフデータベースを利用するケースの一例として、参考になれば幸いです。