Semantic Search をブログに実装した
Semantic Search をブログに実装した。VectorDB (Pinecone) の実験としての意味合いが強い。
技術構成を紹介する。まずはインデックスの更新フローについて。Markdown ファイルで入稿したブログ記事から、Gatsby でビルド時にメタデータを抽出する。メタデータとしては、記事の URL やタイトルを利用する。次に、Cloudflare Workers に HTTP POST リクエストを送信する。Workers ではまず Cloudflare D1 (SQLite) に UPSERT する。この時、db.batch で Prepared Statements をまとめて D1 へのラウンドトリップを一回に抑える。
次はメタデータをベクタライズする。Cloudflare AI binding の BAAI general embedding を利用し、文字列情報をベクター表現に変換し、Pinecone (VectoreDB) に UPSERT する。UPSERT の一度の上限ベクターは 20K と十分なので、現時点では Batching が不要で一回の HTTP API コールで済んでいる。
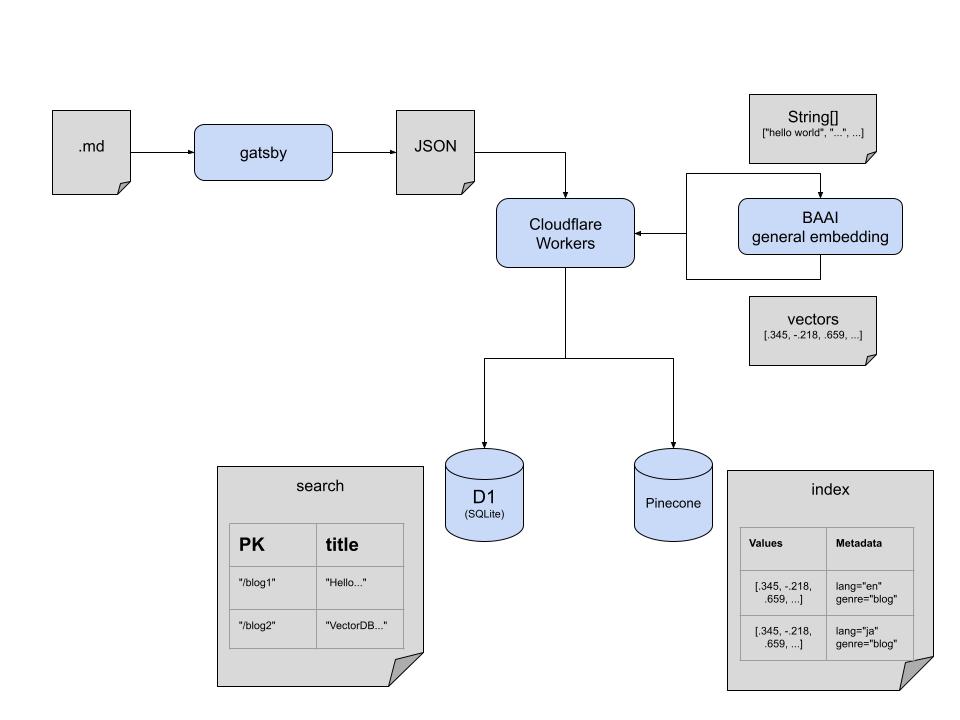
更新フローについて説明したので、次に検索フローについても説明する。Cloudflare Workers に別のエンドポイントを実装し、HTTP POST リクエストで検索タームを受け取る。同じモデルを使って検索タームをベクター表現にした上で、Pinecone にクエリする。この時、英語ブログと日本語ブログで結果を切り分けられるように Metadata を利用している。Pinecone では Single-Stage Filtering を実装している。Single-Stage Filtering は、単純な Pre-filtering での総当たりチェックによる性能劣化と、単純な Post-filtering による検索結果の品質低下を克服しているようだ。
{
"metadata": {
"lang": "(en|ja)",
"genre": "blog"
}
}
実は当初は Pinecone ではなく Neo4j の Vector search index を利用して実装していた。Prototype はうまく行ったので、いざ Cloudflare Workers から利用しようとしたのだが、HTTP ではなく Bolt Protocol を自前実装しているが故にCloudflare のネットワークを超えられない問題にあたって、諦めた。
さて、次は何を実装しようか。データベース好きな Site Reliability Engineer としては、Vectorize など他の VectorDB も比較検討してみたい。他の Text Embedding のモデルを利用したり、ベクターの数を増やしたり、Cosine similarity 以外の Vector Similarity を利用して、検索の精度を高めるチューニングも楽しそうだ。