Dynamic Secondary Hashing
Hot Partitioning 問題
Partition において良く直面する現実の問題の一つが、Hot Partition 問題と呼ばれるものだ。Skewed Workloads や Hot Spots もほぼ同義で利用される。特定のパーティションに負荷が集中してしまい、プラットフォーム全体で見たときに負荷を分散できていない状態だ。
例えば、マルチテナントな EC アプリケーションを構築したとする。Shop ID でデータベースを Partitioning したとしよう。このとき、シンプルに Hash Partitioning を利用していたとする。
さて。超人気ファッションブランドが、一時間限定の大規模セールを行ったとき、Hash Partitioning を利用していた場合、どのような負荷が想定されるだろうか。十分にスケールできるだろうか。
よくある障害パターンとしては、そのファッションブランドのデータが割り当てられた Partition に、セール中に急激に負荷が集中してしまう。データベースがダウンして、そのセールに必要なリクエストを捌けない。それどころか、マルチテナント構成であるが故に、同じ Partition にデータを保存している他の店舗にも影響が出てしまう。
Twitter や Facebook のような SNS の例で言うなら、有名人のアカウントは数百万単位でフォロワーがいるので、普通に Partition してしまうと、その有名人のアカウントのデータを保存する Paritition はパンクしてしまう。このことから、Celebrity 問題と呼ばれることもある。
How to solve Hot Partitioning
では、Hot Partition 問題をどう解決するか。方法はいくつかある。
DDIA 本で紹介されているシンプルな例をまず紹介する。もし特定の key がこのように高負荷になることが想定されているなら、ランダムに生成した整数を付与する案が提案されている。
ただし、このシンプルな解決策にも難点はある。書き込み時の負荷を分散させるメリットを享受できる一方、読み込み時に複数の Partition から分散されたデータを集めなくてはいけなくなるのだ。Read のワークロードのパフォーマンス低下というデメリットとトレードオフである。典型的な gather/scatter パターンだ。
DDIA 本では、このセクションを「近い将来、データシステムが自動で Skewed Workloads を検知して対応してくれるかもしれないが、現状は、各々がトレードオフを加味しながら実装しないといけない」として締めくくっている。
しかし、この本は 2017 年 3 月に上梓された本だ。それから 6 年も経っている。新しい研究結果や成果はないのだろうか。私個人としては、せっかく同じ本の 2 回目の輪読会に参加しているので、何かバリューが出せないかと最新の論文をいくつか漁っていたところ、Alibaba Group と Georgetown University が 2022 に共著した興味深い論文が出てきた。
"ESDB: Processing Extremely Skewed Workloads in Real-time" は、EC サイトをマルチテナントで構築している Alibaba が、まさに上記の例で挙げたような Skewed Workloads に対して、Dynamic Secondary Hashing 及びその他の最適化手法によって、いかにパフォーマンスを向上させているかについて紹介した論文だ。非常に興味深い事例なので、ここで読み解いていきたい。
Problems to solve
Alibaba や Shopify のようなマルチテナントな EC サイトが抱えるパフォーマンス上の課題。それは BFCM のようなセールやプロモーションの時に特にワークロードが Skewed で Unpredictable になるという点だ。つまり、データが一部の Partition に偏り、かつそのスパイクが予測できないということだ。
Another challenge is that the workload distribution in the sellers' database is extremely skewed because of the tremendous variation of the numbers of transactions conducted by different sellers. The variation is further magnified at the kickoff of major sale and promotion events during which the overall throughput increases drammatically.
想像してみてほしい。普段は高々 10K RPM に過ぎないオンラインストアが、一時間限定のプロモーションを全世界のストアで行ったが故に、数百万ものリクエストを瞬時に捌かなくてはいけないのだ。
しかも、商品を購入するという支払いを挟むがゆえに、Read だけでなく Write の負荷も一定数以上見込まれる。Read だけなら、キャッシュを暖めておくだけで解決できる場合も多いが、商品残数があるようなオンラインストアではそうも行かない。
スパイクする書き込みのワークロードはもちろん、殺到する読み込みのワークロードをどちらも良い感じにスケールさせつつ、整合性も保たなくてはいけない、しかもそれが高々一時間の間に洪水のように発生する。こんなに面白い課題はない。
Solution
この論文では、複数の最適化手法も併せて紹介されているのだが、この記事ではその中心である Partitioning の手法、Dynamic Secondary Hashing についてのみ紹介しよう。
しかし、いきなり Dynamic Secondary Hashing について説明する前に、従来の手法について紹介する必要がある。
まず、問題を整理しよう。ここでの問題は、有名人やセール実施中の店舗などの一部の Key (ex. User ID, Shop ID) に割り当てられる Partition に対する書き込みのワークロードが、急激にスパイクする。がゆえに、その Partition が割り当てられたノードがパンクする、と言うことだった。
Double hashing
これを解決する手法の一つに、Elasticsearch や HBase、OpenTSDB で実装されている Double hashing と言う手法が存在する。これは、Hashing を繰り返すことによって、データ量を更に細かく分ける手法だ。
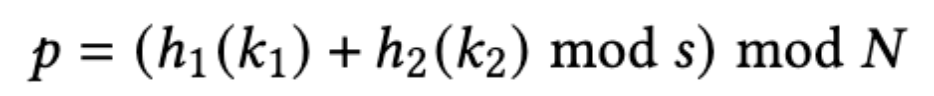
Double Hashing の公式。h1 と h2 はそれぞれ別の Hashing アルゴリズム。k1 と k2 はそれぞれ別の key で、例えば k1 は店舗を区別する Tenant ID、k2 はトランザクション ID。s が重要なレバーで、チューニングポイント。この値が大きければ大きいほど、データをより分散させることができる。一方で、クエリ実行に必要な CPU コストが高まり、データを返すときにより多くのデータを集約する必要があるので、パフォーマンスは低下する。
ここで一つ、アナロジーを紹介してみよう。お肉を食べ始めた幼児期の子どものために、ハンバーグを切ってあげたとする。まだまだ小さくて、そのままの大きさでは口に入らなかったので、子どもにお肉を食べてタンパク質を摂取してもらいたい親としては、もっとチョップしてミンチ上にしてあげてから食べさせてあげる。そんなイメージだろうか。
Double Hashing、良さそうではないか。なぜ Double Hashing ではダメなのか。
そもそも、Hashing と言うのは、細かくすれば細かくすれば良いものではない。確かにデータ量の大きい Partition が分散されるのだが、その代わりに読み取り時のパフォーマンスが下がってしまう。複数の Partition からデータを集めて Aggregate しなくてはならないからだ。gather/scatter だ。
美味しい香りの炭火ハンバーグも、口に入れる前に切りすぎると、肉汁が漏れてジューシーな味わいが失われてしまう。口に入るサイズであるのならば、ぜひそのまま味わいたいものだ。
Dynamic Secondary Hashing
と言うことで、発想としてはシンプルに、「大きい Partition の時だけデータを分散し、小さい Partition はシンプルに Hashing するだけ」で良いのではないだろうか。データ量をリアルタイムに分析して、Hashing するかどうかを動的に変えれば良いのではないのだろうか。今まではデータを分析してデプロイのタイミングごとに "s" パラメーターを変更していたが、それを動的に変更すれば良いのではないだろうか。
そこで Dynamic Secondary Hashing の出番だ。名前の通り、Secondary Hashing(二回目の Hashing)をするかどうかを動的に判断する。
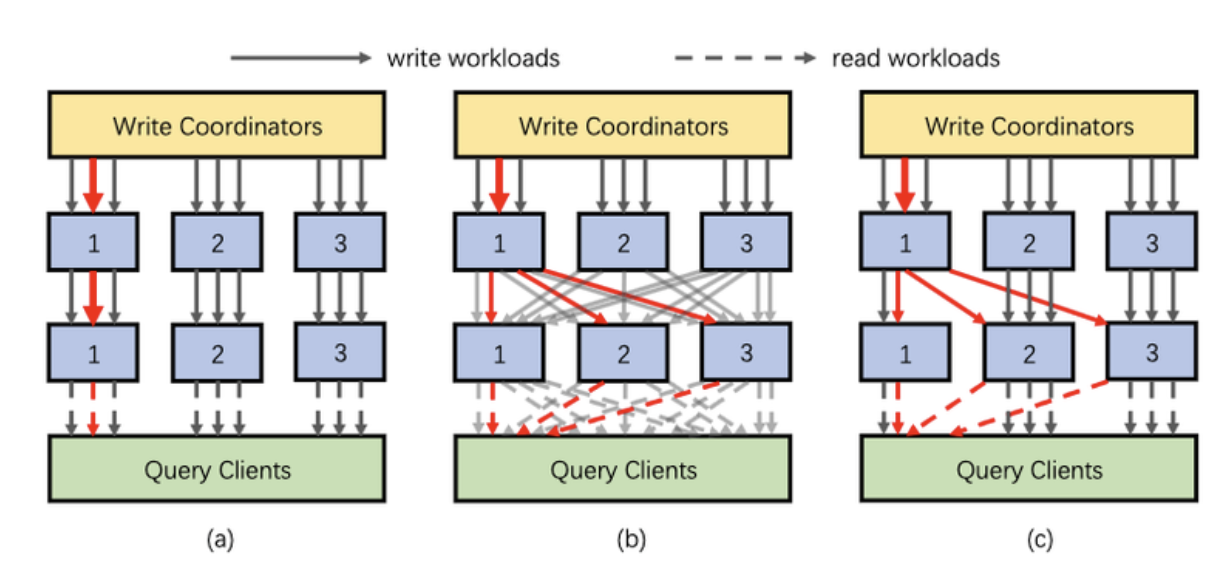
(a) は Hashing。同じ key は同じ partition にしか割り当てられない。(b) は Double Hashing, 全ての key が複数の partition に割り当てられることがわかる。 (c) は Dynamic Secondary Hashing の様子。赤い太い矢印がデータ量の多さを表しており、データ量が多い key だけが Double Hashing されていることがわかる。
Double Hashing の公式を覚えているだろうか。チューニングパラメーター "s" を上げ下げすることで、分散具合とクエリ効率のトレードオフのバランスを取ることができた。Dynamic Secondary Hashing の発想としては、このチューニングパラメーター "s" を、リアリタイムで取得できるメトリクスを利用して、動的に変化させようというものだ。
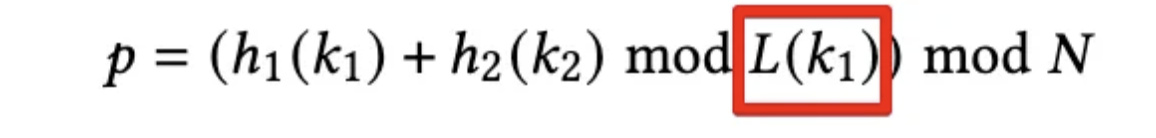
Dynamic Second Hashing の公式。Double Hashing との違いは、分散具合とクエリの効率のトレードオフをチューニングするパラメーターであった s が、L(k1) にとって変わられている。Workload-adaptive offset function と呼ばれる。Key 1 (k1) のリアルタイムのメトリクスを利用して動的に判断するというものだ。
ここでまたハンバーグの例に戻ってみよう。ハンバーグを最初目にした子どもは、それが美味しいのかどうかわからない。大きいままだと食べてくれないので、可能な限り小さいサイズにチョップして与えてあげる必要がある。しかし、炭火ハンバーグの美味しさに目覚めた我が子からの「もっと食べたい」欲求というフィードバックを受けて、チョップする肉片のサイズを変えてみる。システム思考における典型的なフィードバック機構だ。
とはいえ、例の如く Double Secondary Hashing も銀の弾丸ではない。用法・用量を守って正しく使う必要がある。
最大の課題は、Read-your-writes Consistency を破る可能性があるということだ。というのも、Key 1 (k1) のデータがどの Partition に向かうかのマッピングが常に変化するので、過去のどの時点でそれぞれのレコードがどこにあるのかが分からないことだ。
具体的には、別々の Partition に同じデータが重複して保存されてしまったり、分散されたデータを Aggregate したクエリの最終結果が意図しない結果となってしまう。
解決策として、本論文では、過去の Secondary Hashing Rule List をタプルに保存しておくことで、過去のパラメーターの変更に対して遡って計算可能なようにしておくということだ。
これは再起動時に揮発しても良いデータのはずなので、ランタイム中はメモリに保存しておくことになると思うのだが、Workload-adaptive offset function の実装によっては何度もパラメーター "s" が変更され、リストが肥大化していくのではないかと思っている。そこら辺の具体的な実装やデメリットについては紹介されていないが、一つ考慮すべき点ではあるだろう。
またそれだけでなく、整合性を担保するために全ての Coordinator プロセスが同様の Rule List を共有しておく必要がある。したがって、分散システムにおける典型的な合意形成のプロセスを経る必要がある。合意形成アルゴリズムについては実用に耐えうる実装は十分に研究されており、Paxos から Raft、 ZAB など利用できる手法はいくつかある。本論文に関しては、必要十分という理由で Spanner の Commit wait に類似の 2 相コミットの亜種を実装しているとのことだ。
Conclusion
以上、Skewed Workload を検知し動的に Partition を分散させるアルゴリズムとして、Alibaba において導入された Dynamic Secondary Hashing について紹介した。
Double Hashing の "s" パラメーターを動的に変更する手法ということで、Workload-adaptive offset function の実装が肝となってくるだろう。いくつかの実装パターンを試してデータを取得しながら、ビジネス要件やアプリケーションの性質に合った最適なアルゴリズムを各々が探していくという感じになるだろうか。
また、整合性を担保するために考慮しなくてはいけないエッジケースが増えることも一考に値するだろう。一般的にテストが難しい領域なので、このエッジケースをどこまでプロダクションに出す前に潰せるかが、一つ肝となってくるだろう。
もし、Dynamic Secondary Hashing または類似のアイデアを導入している方がいたら、ぜひフィードバックいただきたい。