Neo4j Causal Clustering 紹介
本記事では、Neo4j における Causal Clustering (因果クラスタリング) について説明します。
クラスタリングの目的
データベースを運用する場合、単一のインスタンスを稼働させるか、Causal Clustering を用いてクラスター構成を組むか(クラスタリング)のいずれかを選択することになるでしょう。
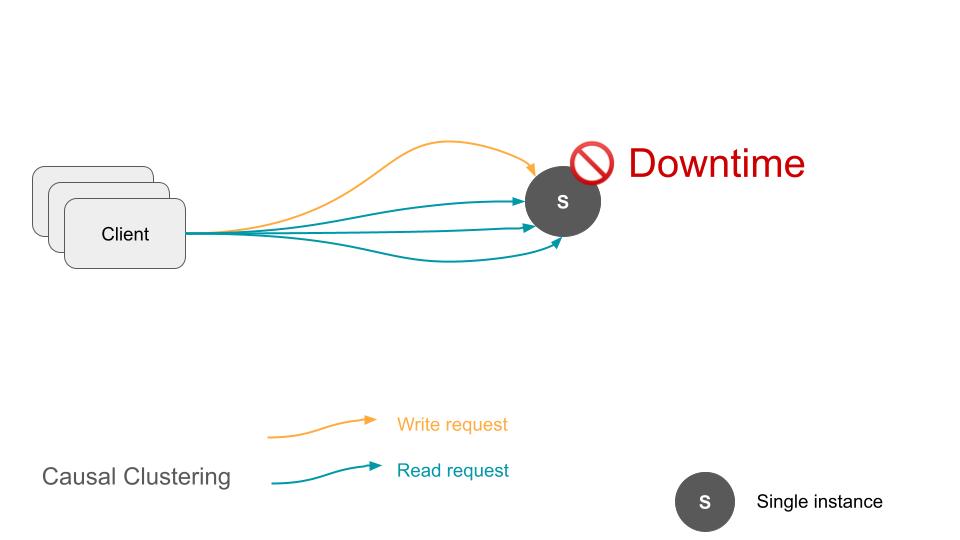
Single Instance のケース
単一のインスタンスを稼働させるのは簡単です。全ての Read/Write リクエストを一つのインスタンスが対応するので、整合性も気にすることがありません。
ですが、本番環境においてすぐに Reliability (信頼性) と Scalability (スケール性) の問題に直面します。単一のインスタンスをどれだけ垂直にスケールアップしても捌ける Request Per Second (RPS) には限界がありますし、そのインスタンスがハードウェア起因やネットワーク起因の障害で不通になってしまった場合、ダウンタイムが発生します。
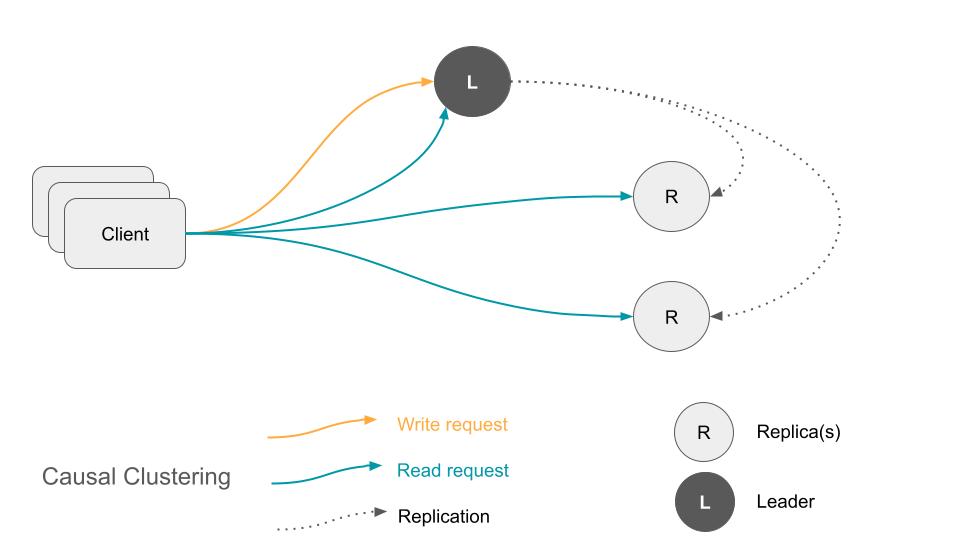
Clustering のケース
そこで、本番環境では基本的にクラスタリングを行います。Neo4j では、Leader ノードが全ての Write リクエストを処理し、Replica ノードをスケールアウトさせることで Read リクエストを処理します。
Reliability に関しては、Leader ノードが故障しても、Raft Protocol と呼ばれる合意形成アルゴリズムを利用して Replica ノードのいずれかを Leader ノードに昇格させることで、ダウンタイムを発生させることなくクライアントからの処理を継続することができます。
Scalability に関しては、Read リクエストの要件に応じて、Replica ノードの数を必要に応じて増やすことで対応できます(Write リクエストに関しては、Writer ノードをスケールアップさせる必要があります)。
Consistency
クラスタリングを行なった場合に気になってくるのは Consistency (結果整合性) です。
データの Replication を非同期で行う場合、どうしても Leader ノードと Replica ノードの間で、ラグが発生してしまいます。例えば、Leader ノードに書き込んだデータを、Replica ノードに同時期に問い合わせた場合、まだ結果が同期されていないので古いでターを返してしまう、という状況です。
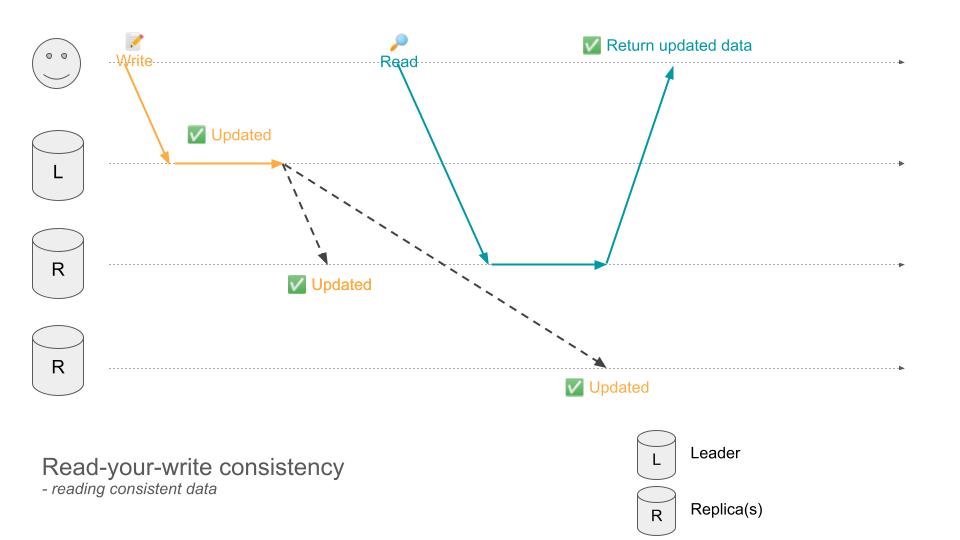
Read-your-write consistency
この問題を解決するためには、Read-your-write consistency と呼ばれる一貫性モデルが求められます。つまり、「自分が書き込んだデータに関しては、必ずその書き込みを反映した一貫性のある結果を返す」ことを保証するモデルです。
例えば、以下のケースを見てみましょう。一つ目の図では、ユーザが Leader ノードに Write リクエストを送信します。Leader ノードでデータの更新が行われた後、それぞれの Replica ノードに同期されます。この時、同期が完了した Replica ノードからデータを読み込んだ場合、ユーザは意図した結果を読み込むことができます。
しかしながら、以下の例ではユーザは古いデータを読み込むことになります。Leader ノードからの同期が完了する前にユーザの Read リクエストが到達してしまうと、更新される前のデータを返してしまうからです。
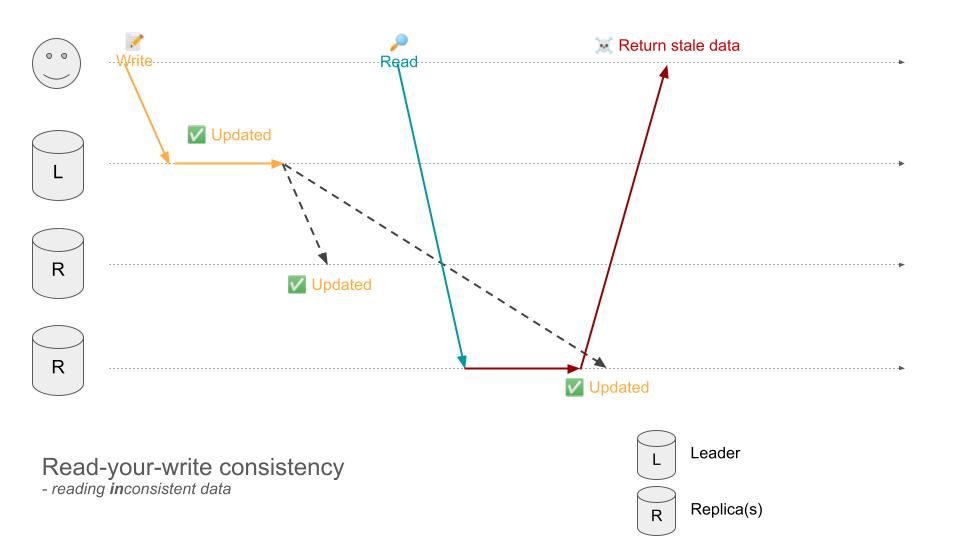
なお、Read-your-write consistency は、他ユーザが書き込んだデータに関しては一貫性を保証していない点には注意してください。例えば、他ユーザが更新した Twitter のプロフィール情報を、別のユーザが見に行ってもまだ更新されていない、というケースは、Read-your-write consistency は何も解決していません。
Causal Clustering における解決策
Neo4j においては、Bookmark と呼ばれる仕組みで Read-your-write consistency を保証しています。
イメージとしては、Write リクエストを含むトランザクションに目印となるタグ(Bookmark)を付与し、一連のトランザクション処理においてそのタグを利用してどのノードで処理するべきかを判別しています。
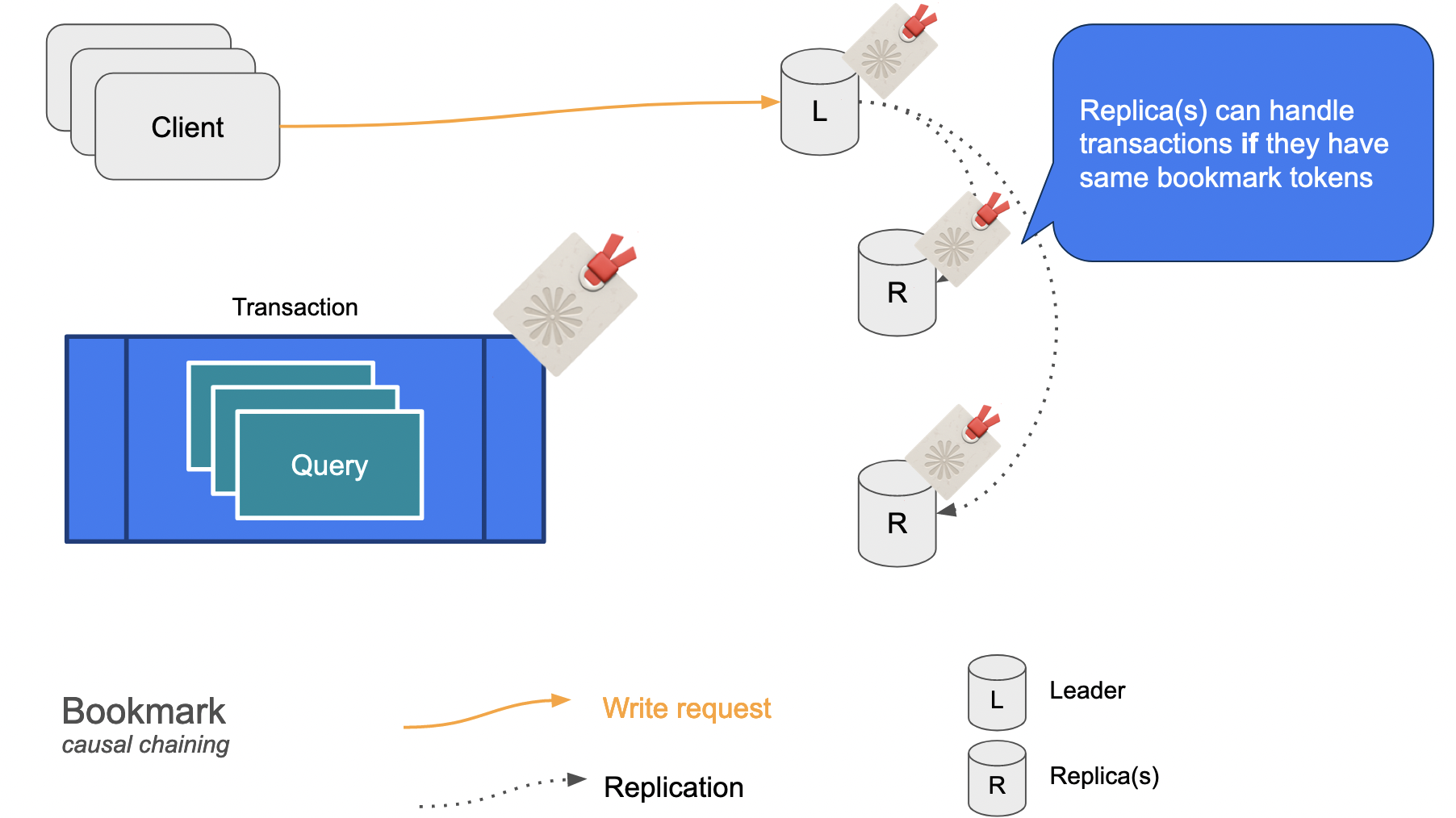
そして、この因果関係 (Causality) が保証されているクラスタリングであることから、Causal Clustering という名称が付けられています。
Summary
以上、Neo4j における Causal Clustering について紹介しました。本番環境でスケール性と信頼性を担保するために不可欠な仕組みです。ぜひ利用してみてください。